ABUNDANT DATA
190 scenes, 97,280 images, 88 objects, 2 cameras

ABUNDANT DATA
190 scenes, 97,280 images, 88 objects, 2 cameras
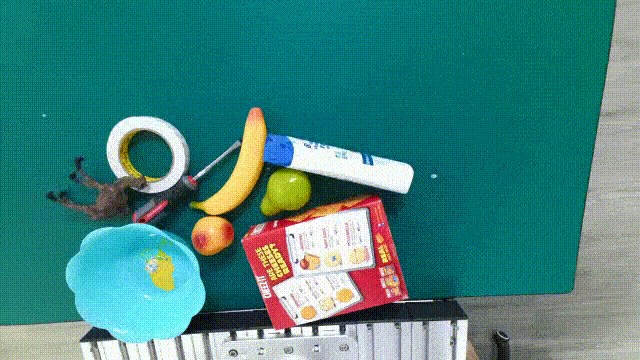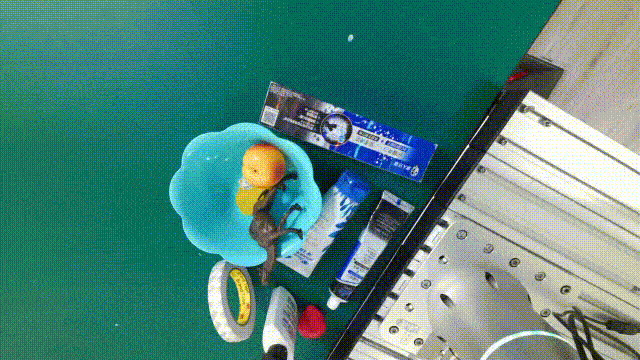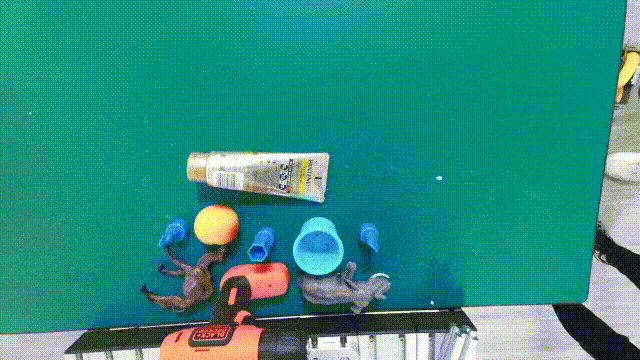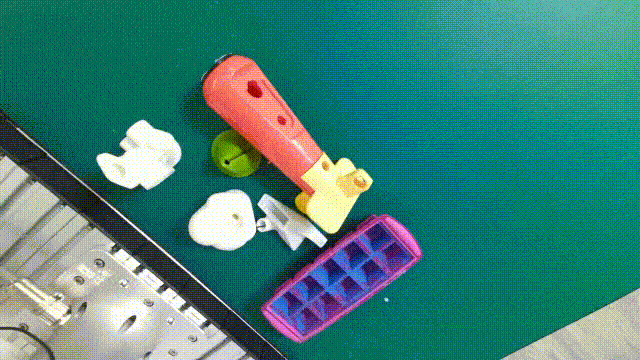
DENSE ANNOTATIONS
6DoF grasp labels, planar grasp labels, 6D poses, instance masks, etc.

DENSE ANNOTATIONS
6DoF grasp labels, planar grasp labels, 6D poses, instance masks, etc.

UNIFIED EVALUATION
Standard evaluation metric for different grasp pose representation

UNIFIED EVALUATION
Standard evaluation metric for different grasp pose representation

